As I'm sure a lot of people know already, PostgreSQL 9.4 will
eventually be released without "native" support for UPSERT.
That said, it's still one of the most common questions on the
excellent #postgresql IRC channel, and people are sometimes
tempted to try and solve it via TRIGGERs (hell, even RULEs),
unsuccessfully.
Even though people are often correctly
told to "use a function" and are pointed to the example in the
documentation, I often find myself needing some more information
about the specific case to give a satisfactory answer.
The tricky part is that due to a race condition, a UNIQUE
constraint is necessary to correctly implement UPSERTesque
operations in Postgres, but unique violations abort the entire
transaction unless a subtransaction is created. Unfortunately,
entering a subtransaction is often said to be expensive, so the
trick is to try and identify cases where you can still implement
the operation correctly without entering a subtransaction
unless absolutely necessary.
So I got curious about the cases where you can get substantial
performance benefits from not entering one, and benchmarked
different concurrency-safe solutions to three of the common
operations I've identified. The three operations are:
- INSERT or IGNORE: INSERT, but if the row already exists,
don't do anything. No result required other than "success".
- INSERT or SELECT: INSERT .. RETURNING, but if the row
already exists, return data from the existing row as the
result instead.
- INSERT or UPDATE: INSERT .. RETURNING, but if the row
already exists, UPDATE .. RETURNING instead.
For the purposes of this post, I'm going to be assuming that
no DELETEs or UPDATEs of the PRIMARY KEY are ever executed on
the target table. Some of the examples would work correctly
in these cases at well, but most of them would need small
adjustments.
For testing, I pre-populated a table with N % of rows
in a range, and then called the UPSERTy function once for every
value in that range. The idea was to get a rough approximation
of the performance in "the row exists in N % of operations" for
different values of N. You can find all the code I used
here. Have eye
bleach (or a fork) handy if you plan on looking at the bash scripts,
though.
INSERT or IGNORE
For INSERT or IGNORE, I came up with three different solutions.
The first variant first sees if the row exists, and if it doesn't it tries
the INSERT in a subtransaction. This approach avoids having to enter a
subtransaction if the value clearly already exists. The hypothesis was
that this approach would be fastest if the value exists at least on every
second attempt.
The second approach simply always enters a subtransaction and attempts to
INSERT the record, ignoring the unique_violation exception if the row already
exists. This is probably the fastest approach if most of the time the row
does not already exist.
Finally, the last variant does an INSERT .. WHERE NOT EXISTS in a
subtransaction. I expected this to be slightly faster than the previous
approach in some cases, but slower in almost all cases.
Here are the results:

As you can see, at ~40% of rows existing avoiding the subtransaction is starting
to become a performance gain. Perhaps slightly surprisingly, INSERT ..
WHERE NOT EXISTS in a subtransaction doesn't seem to ever make sense.
INSERT or SELECT
To implement INSERT or SELECT, I came up with a total of four solutions.
The
first
three
are the equivalents of INSERT or IGNORE, as described above, and
the last one uses a LOOP instead of copying the lookup directly into the exception
handler block. I had no hypothesis on which one would be faster between the
first one and the last one; I was just curious to see if there was any difference at all.
The fourth version also supports DELETEs, unlike any of the other versions.
Results:

The ideas here look very similar to the INSERT or IGNORE case, though skipping
the subtransaction makes sense even earlier, at around 30% of rows pre-existing in
the target table. No clear difference between methods one and four, not
surprisingly.
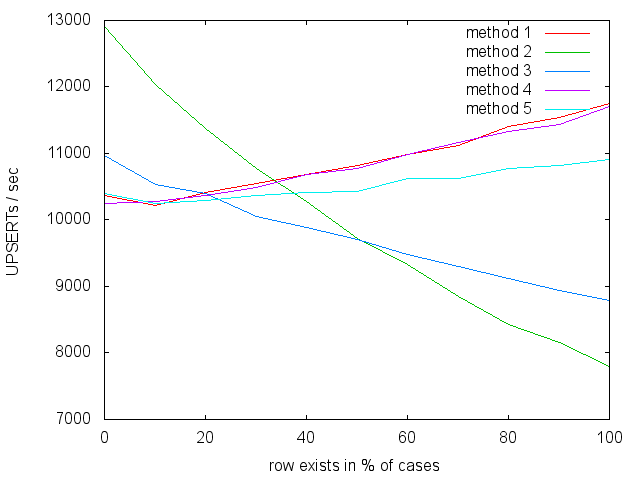
INSERT or UPDATE
For the "traditional" UPSERT I just implemented
the
same
approaches
as for
INSERT or SELECT. Again, the fourth approach supports DELETEs.
Results:

Very similar results here as well, though methods one and four don't get that
big of a benefit anymore from the row existing compared to how fast they are
against an empty table. Subtransactions are still expensive, though.
Conclusion
According to these results, you might want to consider avoiding the subtransaction
if you expect the target row to exist roughly 30% of the time. Definitely consider
that approach if you expect the row to exist in anywhere above 40% of cases.
Please remember that these results can only provide a general guideline.
In particular, the behaviour was not tested under any actual concurrency (other than
manual tests to verify correctness). If performance is very important for you,
it's always up to you to measure different solutions and choose the one that works best
for your application!
Update: Joel Jacobson suggested a slightly different variant in the comments,
and I've added it to the
graphs
in the git repository. The results further highlight the fact that it's not the act of
entering a subtransaction that's expensive, it's failing one and recovering from it.
That also means that benchmarking these variants under concurrent workloads is likely going to
give slightly different results.

{kind=link}